【バイオ × 生成AI】タンパク質の設計を倍速にする生成AI サービス:Cradle
- 生成AI
- LLM
- バイオ
新たなタンパク質の発見に役立つ生成AIサービス:Cradleを徹底解説!


通常、新たな機能・特性を持つタンパク質の生成には、多くの時間と膨大な回数の試行錯誤が必要になります。こちらのサイトでも、「タンパク質の構造を実験によって決定するには、多くの時間と費用がかかる」と書かれています。
タンパク質の設計や発見に時間がかかる理由としては様々挙げられますが、わかりやすい例がJAXAによる下記の記事で取り上げられています。
“””
私たちは頭が痛くなったり、熱が出たりすると、薬を飲みます。薬の役割は、体内のタンパク質に結合して、タンパク質の働きを調節することなのです。
しかし、私たちの体内には10万種ものタンパク質が存在しているため、せっかく標的のタンパク質を上手く調節する分子が見つかっても、病気とは無関係の他のタンパク質にも結合できるようだと、他の機能が阻害され身体に悪影響が出てしまいます。数あるタンパク質のうちから、ある特定のものだけを狙って結合し、しかも機能も調節できる分子を探すというのは非常に大変な作業です。
“””
上記の例は医薬品開発の文脈におけるタンパク質の研究の大変さを表していますが、生命現象の解明や産業用酵素の開発においても同様のことが言えます。
どういうタンパク質配列の並びで、どういった条件が揃った時に特定の現象が生じるのかを解明し、それによる影響範囲を調べて問題がないかを確認する、という作業は、多くの実験回数を要する作業です。
今回は、生成AIに基本的なタンパク質工学の知識を学習させ、設定条件と実験結果から、仮説構築と検証をスピーディに回すことができるサービス、「Cradle」を紹介します。
Cradleの概要
Cradleはオランダのアムステルダムとスイスのチューリッヒに拠点を置く、バイオテックスタートアップです。
CEOのStef van Grieken氏は、Google Research & Machine Intelligence でシニアプロダクトマネージャーを務めていた経験があり、機械学習のスペシャリストでもあります。
Cradleは2023年11月末、シリーズAラウンドで2,400万ドル(約35億円)の資金調達を行いました。この資金は、機械学習エンジニアチームやバイオテクノロジーチームの拡大に加え、アムステルダムに追加の実験室とエンジニアリング施設を建設するために使用されるようです。(引用:https://www.cradle.bio/blog/cradle-raises-24m-series-a-and-signs-partnerships-with-industry-leaders )
Cradlはすでに10を超えるプロジェクトを実施している最中とのことですが、その中の大口顧客としてJohnson&Johnsonやnovozymesといった大手医薬品企業も存在しており、Cradleの持つ技術は大手企業からも注目されていると言えます。
Cradleの機能
Cradleのサービスページでは、いくつかの機能が紹介されています。
トップページでは「推測に頼らないタンパク質のエンジニアリング」とキャッチコピーが記載されており、その下にはターゲットとなるタンパク質配列・安定性・活動範囲を指定することで、バリアント(タンパク質の並びが変異したもの)の作成を体験できるような仮想デモがあります。

(引用:https://www.cradle.bio/ )
また、タンパク質と一口に言っても、Cradleは酵素・ペプチド・ワクチン・抗体など、様々な用途に使用できます。その使い方は機械学習に精通していない人でもわかりやすいようにWebベースで設計されており、メインの機能は以下の4ステップのみで構成されています。
1.アッセイと目的を設定する
プロジェクトを成功させるために、何を測定するかや、その測定値をどのように活用するのが目的かをCradleに入力する。(アッセイ… 実験対象の存在、量、または機能的な活性や反応を、定性的に評価、または定量的に測定する方法のこと)
2.シーケンスを生成する
ボタンをクリックすると、タンパク質のそれぞれの特性に対して予想されるパフォーマンス予測とともに、指定された目的のためにさらに改善されたシーケンスが得られる。
(シーケンス… アミノ酸配列やDNA塩基配列など、構成単位の配列のこと)

3.ラボでのテスト
シーケンスが生成された後に、新しいバリアントをラボ(Cradle内の実験場所)でテストします。Cradleはテスト結果が新たな仮説の生成に役立つと説明しており、新たなラボでテストするごとに目的のタンパク質の発見に近づきます。

4.ラボ結果をインポートする
実験データを Cradle にインポートして終了します。これによりプライベートCradleモデル(Cradleのラボで扱う実験データは、他のラボで扱うモデルに追加学習されませんし、他社にデータや知見が漏れることもありません)が改善され、次のテストで期待されるパフォーマンスについての洞察が得られます。
3と4を何度も繰り返していくことで、テストした結果から生成AIが、次のテストで試す条件やパターンを仮説として構築し、再度検証することができます。これにより、最終的に求めているタンパク質の配列を特定することができます。
Cradleを使用したデータ収集ガイド
Cradleはユーザーがサービス使用時に誤解しやすい部分を、データ収集ガイドとしてまとめています。こちらを読むことで、Cradleを使ってどのように研究を進めていけば良いか、より解像度が上がるでしょう。
誤解1:タンパク質の生成MLモデル(生成機械学習モデル)をトレーニングするには、大量のデータセットが必要である
この考え方は、部分的に正しいと言えます。普通の大規模言語モデルにはタンパク質の設計についての知識が実務で扱えるほどのレベルではないため、最初の学習においてはデータ量が多いほどモデルは賢くなります。
しかし、Cradleは自社の研究室から得られた約10億のデータセットをすでに学習済みであり、タンパク質に関する基本的な規則は理解している状態です。
そのためユーザーが使用する際には、改善したい特性ごとに約96個のタンパク質配列バリアント(高品質なデータセットにあたる)を一貫した条件でテストすれば、どの用途に対しても対応できる生成ML(機械学習)モデルが生成できることがわかっています。
誤解2:AIを使用すると、ワークフロー全体(DBTLプロセス)が混乱する
バイオエンジニアリングチームで行われる実験は通常、DBTLプロセス(Design, Build, Test, Learn)に則ってサイクルを実行するように設計されています。生成 AIを使用するとこれらのプロセスが無視され、生成AI専用の独自のプロセスに取って代わり、検査装置や施設への投資が無駄になるのではないか、という疑問を持たれるようです。
Cradleを使ったからと言ってDBTLプロセスが不要になってしまうということはなく、「設計(Design)」と「学習(Learn)」の部分をより洗練させることで、各ラウンド(シーケンス生成からラボ結果に至るまで)での成功確率を高めます。
従来であればタンパク質エンジニアは、1配列に対して最大3つの変異を含めるように実験を行いますが、Cradleを用いると、さらに多くの突然変異を含めて実験することができます。
また、先ほども述べましたがCradleはテスト結果から次の仮説を構築する能力が優れていると公言しており、自分で設計アイデアを考えるよりも、テスト結果から合理的な設計を自動で構築してくれます。
時には人間にとっては直観的でない設計であっても、モデルの大量の過去データセットから導き出される設計は、何らかの意図がある設計になります。結果的に人間が設計するよりも速く、目的のタンパク質配列に辿り着くことができる可能性が高いです。

(引用:https://www.cradle.bio/blog/data-collection-guide )
誤解3:生成MLモデルのデータは完璧でなければならない
機械学習を行うときによく耳にする言葉の一つに、「インプットが適切でない時点で、アウトプットも悪いものになる(ゴミを入れるとゴミが出てくる)」という言葉があります。
これはCradleのような生成MLモデルにも同様のことが言えるのですが、Cradleはアッセイの誤差範囲がある場合、それをモデルのパラメーターに加味することや、信頼性のない測定値に対して重みづけを軽くすることで、データの品質を向上させる仕組みを持っています。
データの品質が低いと思われる場合は、テストを何度も反復することで学習が進み、データの信頼性を徐々に向上させることができます。
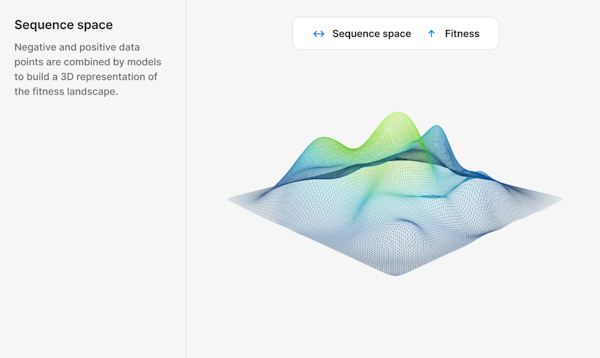
誤解4:ネガティブなデータは役に立たない
ここでいうネガティブなデータというのは、目的の性質を持つ、タンパク質配列の特定をするために、有効な手掛かりにはならないような、意味のないデータのことです。
この考えは間違いであり、生成MLモデルはパフォーマンスの高いデータよりも、多様性のあるデータを重視します。これは、多様なシーケンスを与えることでパフォーマンスを向上させる要因と低下させる要因を識別できるようになるためです。
つまり、パフォーマンスの高いタンパク質シーケンスは、さらに調査すべき領域をモデルに学習させることに役立ちますが、パフォーマンスの低いシーケンスも、どの領域を避けるべきかを学習させることに役立っています。
(引用:https://www.cradle.bio/blog/data-collection-guide )
誤解5:ML(機械学習)はすぐに良い結果をもたらす
Cradleの生成MLモデルは、初めの状態は何も特別な訓練がなされていない、一般的なタンパク質設計の基礎概念を理解しているだけのモデルです。そのため、特定のタンパク質に対して知見があるわけではありません。
しかし先ほども述べたように、Cradleのモデルは仮説構築能力が優れているため、約96個の優れたデータセットを与えることで、特定のタンパク質の知見を有する専門家になります。
これらの誤解を事前に解消しておくことで、Cradleの生成MLモデルがどういった特徴を持っていて、どのように使用していけば良いのかを、より把握できるようになるのではないでしょうか。
まとめ
Cradleはタンパク質の設計に特化した生成MLモデルを構築することで、タンパク質の設計にかかる時間・費用を削減していることがわかりました。
弊社でも大規模言語モデルに専門知識を埋め込む「RAG」という技術には一定の知見があります。また、非構造・半構造のデータを構造化・正規化することにも強みを持つ会社です。
それらの技術を活かしたプロジェクト組成やMVP開発のご支援も行っておりますし、「そもそもどのような業務に生成AIを活用できそうか」という上流工程から伴走することも可能です。「情報収集も兼ねて相談したい」というお客様も、お気軽にお問い合わせください。
「生成AIを活用したいが、どういう業務に向いているのかがわからない」
「生成AIに興味はあるが、キャッチアップをしている時間がない」
という方々に向けて、最新記事のアップ時にメールでお知らせさせていただいております。
今回の記事のような内容をタイムリーに知りたい場合は、 ぜひ下のフォームからAI Powered Business Lettersに登録いただければ幸いです。